
Während Künstliche Intelligenz schon längst tief in unseren Alltag eingreift, herrschen in breiten Teilen nicht nur der allgemeinen Öffentlichkeit diffuse Ratlosigkeit und Besorgnis, gepaart mit ebenso diffuser Zukunftshoffnung.
Das Kompetenzzentrum Öffentliche IT (ÖFIT) des Fraunhofer-Institut für Offene Kommunikationssysteme FOKUS hat daher das Bündel einmal aufgeschnürt und bewertet die einzelnen Stränge. Dabei konzentrieren sie sich auf Anwendungsbereiche und Potenziale und geben, unterstützt durch eine Experten-Community, Prognosen, wie lange es dauern könnte, bis die jeweilige Technologie ihren Durchbruch erzielen wird.
Die Autoren Christian Welzel und Dorian Grosch stellen im IT-Channel von buchreport.de die wichtigsten Fakten aus dem „ÖFIT-Trendsonar“ vor. Auch zu Fragen der gesellschaftlichen Akzeptanz haben sie Verbraucher und Experten befragt und schließen in Teil 2 mit einem Bündel von Empfehlungen für Wirtschaft und Politik.
Die Zukunft ist schon da, sie ist nur ungleich verteilt (William Gibson).
Künstliche Intelligenz – zwischen Hype und Zukunftstechnologie
Kaum eine Entwicklung innerhalb der Digitalisierung bietet so viel Stoff für Utopien und Dystopien wie die Künstliche Intelligenz (KI). Mal übernehmen Roboter die Macht über die Menschheit, mal wird mit KI ein Heilmittel gegen Krankheiten entwickelt. Doch schon der Begriff Künstliche Intelligenz ist schwierig, da bereits eine allgemeingültige Definition des Begriffes Intelligenz fehlt. Entstanden ist der Begriff der Künstlichen Intelligenz 1956 in den USA. Im Rahmen eines Sommerseminars wurden am Dartmouth College unterschiedliche Programme vorgestellt, die komplexe Aufgaben ausführten, wie beispielsweise eine Partie Schach oder Dame zu spielen.
Heute ist Künstliche Intelligenz eher ein Sammelbegriff als eine konkrete Technologie oder Disziplin. In der Literatur wird dabei häufig zwischen schwacher KI (Lösung eines konkreten Problems, einer konkreten Fragestellung) und starker KI (Abbildung menschlicher Intelligenz) unterschieden. Aktuelle KI-Lösungen fokussieren auf eine definierte Aufgabe und sind damit der schwachen KI zuzuordnen. Die Entwicklung einer starken KI, die tatsächlich menschliches Bewusstsein und Denken vollständig emuliert, ist derzeit weder realistisch noch absehbar und daher außerhalb der Betrachtung dieses Trendsonars.
Mit Verfahren der schwachen KI werden Abläufe automatisiert oder Entscheidungsgrundlagen geschaffen. Dabei können beachtliche Erfolge erzielt werden. KI-Technologien können schneller als ein Mensch große Datenmengen nach Informationen durchsuchen oder Muster erkennen. Darüber hinaus werden Methoden und Technologien der KI in vielen Bereichen eingesetzt, etwa bei der Sprach- und Bilderkennung oder der Vorhersage von Ereignissen, wie beim Predictive Policing oder bei Börsenkursen. Die Entwicklung der KI war lange Zeit Gegenstand universitärer Forschung. Heute wird die Entwicklung auch aus kommerziellem Interesse vorangetrieben, was die Forschungsetats großer IT-Konzerne und die stark zunehmende Anzahl digitaler Assistenten wie Siri, Google Now oder Alexa zeigen. Die Fortschritte in der KI-Forschung sind im Wesentlichen auf drei Ursachen zurückzuführen:
- Verfügbarkeit umfangreicher Trainingsdaten: Die Zunahme datenbasierter Geschäftsmodelle und die nahezu unbeschränkte Verfügbarkeit von Speichervolumen führen dazu, dass immer umfangreichere Datensammlungen entstehen, die wiederum als Trainingsdaten für KI-Anwendungen genutzt werden können.
- Optimierte Verfahren der Daten-Analyse: Mit Big-Data-Ansätzen können große Datenmengen effektiv analysiert werden. Die Verfahren der KI ermöglichen es dann, Zusammenhänge oder Muster zu identifizieren.
- Kommerzielle Verwertbarkeit: Die Kombination aus umfangreichen Datensammlungen, effektiven Algorithmen sowie steigender Rechenleistung ermöglicht es, KI-basierte Produkte zu entwickeln. Dies wiederum unterstützt die Entwicklung von KI-Technologien, wenn beispielsweise spezifische Hardware für maschinelles Lernen entwickelt wird.
Heutige Lösungsansätze orientieren sich in der Regel an natürlichen Prozessen. Methoden des maschinellen Lernens beispielsweise versuchen, die Struktur des menschlichen Gehirns mittels künstlicher neuronaler Netze nachzubilden. Anhand von Trainingsdaten „lernt“ das System, seine Aufgabe zu lösen. Hierfür ist nicht nur eine große Anzahl an Trainingsdaten entscheidend, sondern auch deren Gestaltung. Berücksichtigt werden muss dabei, dass bestimmte kulturelle Prägungen oder Vorurteile der Entwickler sich in den Trainingsdaten wiederfinden können. Bei ausreichend vielen und gut ausgewählten Trainingsdaten bieten diese Lernmethoden jedoch eine sehr hohe Trefferwahrscheinlichkeit, beispielsweise wenn es darum geht, bestimmte Objekte oder Personen auf Bildern zu erkennen. Bei der Interpretation der Ergebnisse müssen zwei Punkte berücksichtigt werden: Zum einen arbeiten viele Verfahren als Black Box, bei denen nicht nachvollziehbar ist, wieso das System zu einem bestimmten Ergebnis gekommen ist. Zum anderen liefern die Verfahren nur ein wahrscheinliches, aber kein gesichertes Ergebnis. Mit anderen Worten, es kann auch einmal vorkommen, dass sich das System „irrt“.
 IT-Grundlagen und Technologien der Zukunft
IT-Grundlagen und Technologien der ZukunftMehr zum Thema IT und Digitalisierung lesen Sie im IT-Channel von buchreport und den Channel-Partnern knk und Rhenus. Hier mehr
Wer KI einsetzen will, muss die zugrunde liegenden Methoden kennen und bewerten können. Mit diesem Trendsonar wollen wir Ihnen nicht nur einen Überblick über aktuelle und künftige KI-Verfahren geben. Eine detaillierte Einschätzung zu Zukunftsfähigkeit, Reifegrade, Marktdurchdringung, Standardisierung und Verfügbarkeit bieten Ihnen einen fundierten Einblick in den aktuellen Entwicklungsstand. Das ÖFIT-Trendsonar KI richtet sich an Entscheidungsträger aus Politik, Wirtschaft und Verwaltung, sowie an alle technisch Interessierten.
Das ÖFIT-Trendsonar im Überblick
In diesem ÖFIT-Trendsonar haben wir 28 Technologien und Lösungsansätze aus dem Forschungsfeld der Künstlichen Intelligenz analysiert. Das Trendsonar bietet Ihnen einen Überblick über wichtige derzeitige und zukünftige Verfahren und Ansätze in den Bereichen
- Lernmethoden,
- Technologien und Algorithmen sowie
- Systeme und Architekturen.
Die Einteilung in diese drei Kategorien ist nicht immer trennscharf, hilft jedoch bei der Orientierung in diesem hochdynamischen Feld. Jeder Technologietrend wurde anhand mehrerer Ausprägungen bewertet.
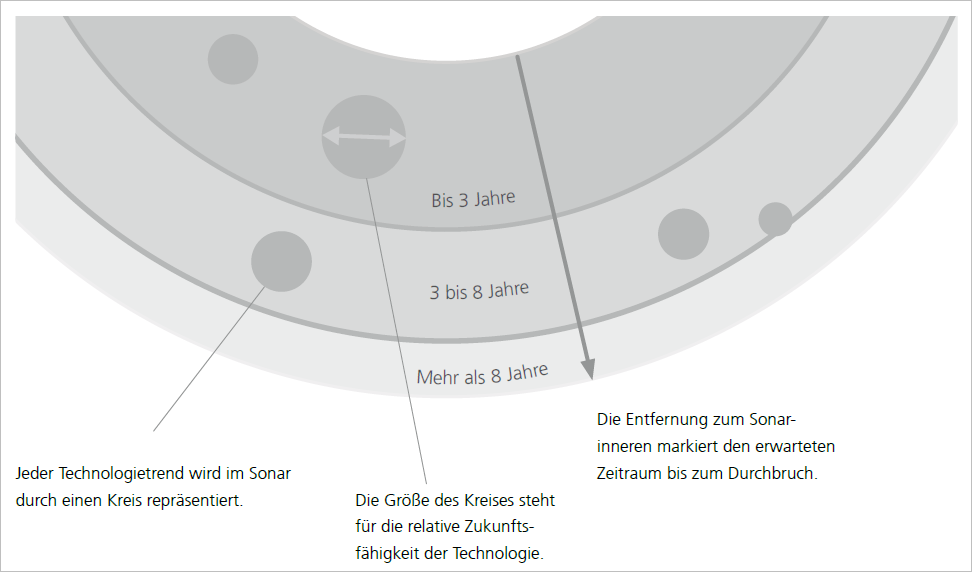
Abb. 1: Das ÖFIT-Trendsonar. Schematische Darstellung. Grafik: Fraunhofer Institut FOKUS.
Als zentrale Bewertungskriterien werden die Zukunftsfähigkeit und der Zeitraum bis zum erwartbaren Durchbruch der Technologie dargestellt (s. Abbildung 1):
Unter Zukunftsfähigkeit wird die Zeitspanne verstanden, innerhalb derer die Technologie oder Methode voraussichtlich noch eingesetzt wird. Je niedriger der Wert, desto eher ist absehbar, dass sie durch eine Alternative ersetzt wird.
Der Zeitraum bis zum Durchbruch gibt an, wie viele Jahre es noch dauern wird, bis der Technologietrend als zuverlässig, technologisch robust und effektiv einsetzbar gilt. Mit dem Durchbruch wird eine signifikante Verbreitung möglich.
So ergibt sich auf einen Blick, wann eine technologisch reife Lösung mit welchem Potenzial für eine dauerhafte Umsetzung zur Verfügung steht.
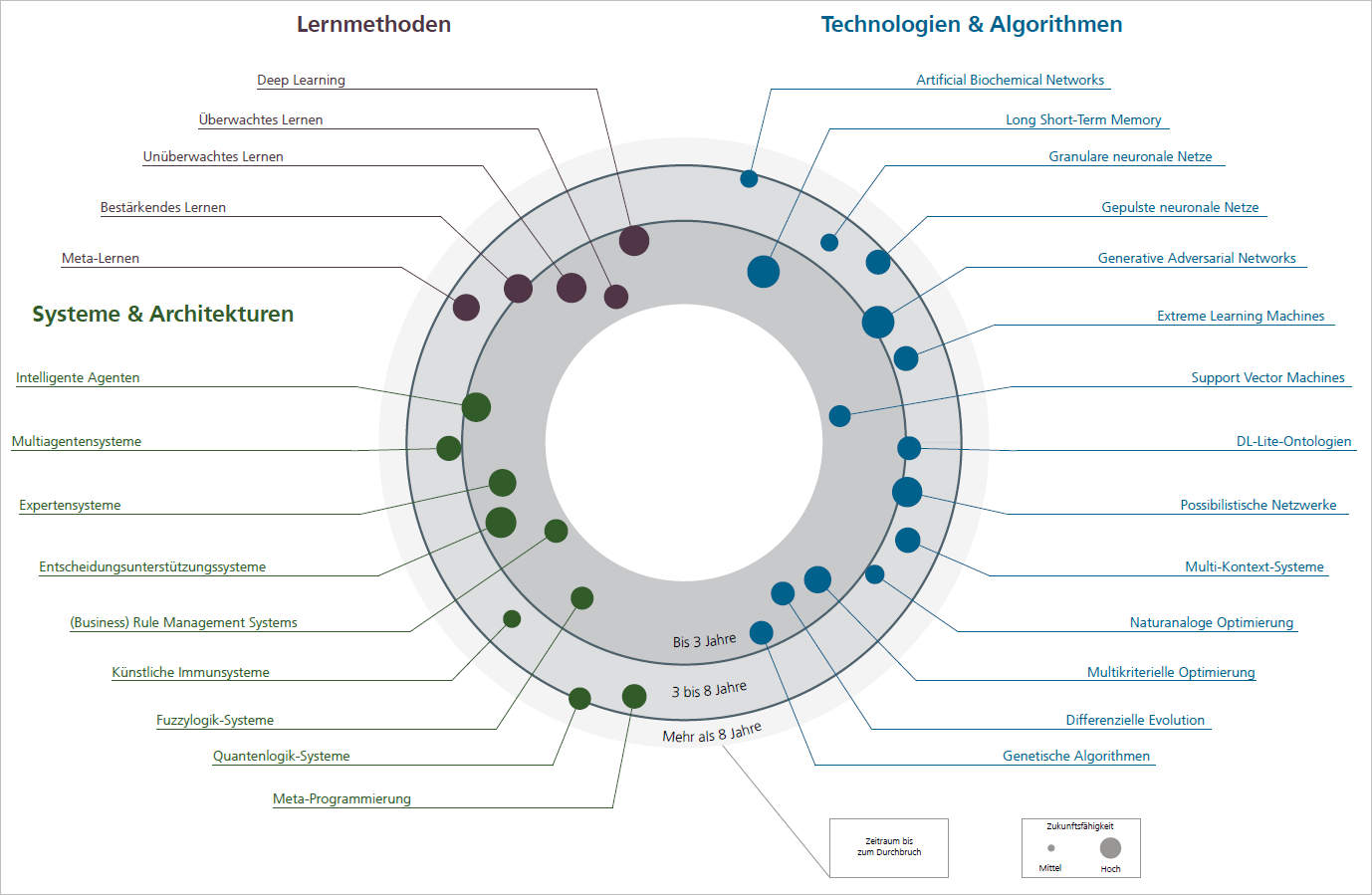
Abb. 2: Das ÖFIT-Trendsonar. Grafik: Fraunhofer Institut FOKUS.
Das ÖFIT-Trendsonar im Detail
Der Überblick wird ergänzt durch weiterführende Bewertungen der einzelnen Technologien. Für den Einsatz von KI-Technologien in der Praxis sind nicht nur zukunftsbezogene Aspekte von Bedeutung, auch die Marktstruktur und die Möglichkeiten zur Einbindung in bestehende Systeme spielen eine große Rolle. Als Anhaltspunkte zur Beantwortung solcher Fragen werden zu jedem Technologietrend neben der Zukunftsfähigkeit die Verfügbarkeit entsprechender Produkte (Angebotsseite), ihre Marktdurchdringung (Nachfrageseite), der Entwicklungsstand (Reifegrad) und der Standardisierungsgrad der Technologie bewertet. Auf Basis dieser fünf Kriterien erfolgt eine zukunftsbezogene und praxisrelevante Einschätzung von Technologietrends. Die fünf Bewertungen wurden von Expertinnen und Experten aus dem Bereich der KI-Forschung und KI-Entwicklung eingeschätzt. Sie werden in Form eines Netzdiagramms wiedergegeben (s. Abbildung 2).
Ergänzend werden quantitative Kenngrößen dargestellt. Hierzu wurden Daten aus Forschungsförderprogrammen auf Bundes- und EU-Ebene, aus Gründungsplattformen, aus Normungs-, Patent- und wissenschaftlichen Literaturdatenbanken, aus Suchmaschinenanfragen und aus dem Social-Media-Bereich herangezogen.
In der Gesamtschau der zukunfts- und gegenwartsbezogenen Einschätzungen sowie der quantitativen Indikatoren ergeben sich Hinweise für die Anwendung der skizzierten Technologien.
Erfolge bei der Entwicklung von KI könnten das größte Ereignis in der Geschichte der Zivilisation sein. (Stephen Hawking)
Zukunftsfähigkeit
Die Zukunftsfähigkeit einer Technologie bezeichnet die Zeitspanne, innerhalb derer die Technologie voraussichtlich noch eingesetzt wird. Je niedriger die Einschätzung der Zukunftsfähigkeit ist, desto eher ist absehbar, dass die Technologie durch eine Alternative ersetzt wird. Im Bereich der Künstlichen Intelligenz basiert der wissenschaftliche Fortschritt auf mathematischen und experimentellen Erkenntnissen. Die Zukunftsfähigkeit neuer Methoden hängt somit von der Entwicklung der Forschung ab. Grundlegende mathematische Werkzeuge der Künstlichen Intelligenz können über lange Zeiträume hinweg im Einsatz bleiben, weil sich ihre Korrektheit nicht ändert, gleichwohl aber können sie in ihrer Relevanz abnehmen.
Reife
Reife bezeichnet den geschätzten Entwicklungsgrad einer Technologie. Je höher dieser Wert eingeschätzt wird, desto ausgereifter ist die Technologie oder Methode. In der KI ist es schwer einzuschätzen, wann eine Technologie vollständig entwickelt ist, denn spätere Erkenntnisse in einem anderen Teilbereich der KI-Forschung können weitere Fortschritte hervorrufen. Deswegen hängt der aktuelle Reifegrad vom momentan wahrgenommenen Potenzial der Technologie ab, welches sich durch wissenschaftlichen Fortschritt kontinuierlich verändern kann. Wird eine Technologie über einen bestimmten Zeitraum hinweg großflächig eingesetzt und hat sich bewährt, so wirkt sich dies ebenfalls auf den Reifegrad aus.
Angebot
Die Kenngröße Angebot bezeichnet die Verfügbarkeit von Produkten, die auf der Technologie bzw. Methode basieren. Je höher der Wert, desto vielfältiger ist die Angebotslage. Die Nutzung von einzelnen Technologien in KI-Lösungen ist meist schwer zu erheben, da diese oft als Gesamtpaket angeboten werden. Da die Einstiegsschwelle für die Entwicklung neuer KI- Technologien durch die Fülle von Entwicklungsplattformen niedrig ist, ist bei geringem Angebot einer Technologie Vorsicht geboten. Allerdings ist zu beachten, dass kleine Technologieanbieter, wie sie im KI-Bereich verbreitet sind, gegebenenfalls über eine geringe Sichtbarkeit verfügen und das Angebot deswegen als kleiner wahrgenommen wird als es ist.
Nachfrage
Die Nachfrage nach einer Technologie ist eine Kenngröße für den Bedarf an KI-Lösungen. Eine geringe Nachfrage für eine zukunftsfähige Technologie kann mehrere Ursachen haben. Vor allem sehr neue Technologien sind bei Kunden oft nicht gut bekannt und können als riskant eingeschätzt werden. Der Markt für KI-Software entwickelt sich schnell, sodass ein Überblick über alle Technologieangebote unerlässlich für die Auswahl einer passenden Lösung ist.
Standardisierung
Standardisierung spiegelt die Einschätzung zum Standardisierungsgrad einer Technologie wieder. Je höher der Wert, desto etablierter und zahlreicher sind verfügbare Standards. Standardisierung trägt zu höheren Qualitätsniveaus und zu verbesserter Interoperabilität bei. Im Bereich der Künstlichen Intelligenz ist der Standardisierungsgrad über das gesamte Feld hinweg geringer als in anderen Teilbereichen der Informatik. Die Notwendigkeit für einheitliche Standards und Normen in der KI wächst jedoch mit ihrem praktischen Einsatz.
Das Feld der Künstlichen Intelligenz ist sehr dispers, sodass viele Kombinationen der Kenngrößen Zukunftsfähigkeit, Reifegrad, Angebot, Nachfrage und Standardisierung aufzufinden sind. Zwischen diesen Aspekten gilt es, ein gutes Gleichgewicht für das eigene Anwendungsszenario zu finden.
Lernmethoden
In diesem Abschnitt werden Lernmethoden aufgeführt, mit denen KI-Systeme trainiert werden können. KI-Systeme zeichnen sich meist durch hohe Komplexität der Teilkomponenten aus, die im untrainierten Zustand jedoch noch keine verwertbaren Ergebnisse produzieren. Erst mit dem Training durch Daten und Lernmethoden entstehen die Fähigkeiten des KI-Systems. Die Lernmethoden sind dabei für jeweils unterschiedliche Anwendungsfälle geeignet, jedoch können insbesondere unkonventionelle Ansätze Durchbrüche in der Forschung und Entwicklung hervorrufen.
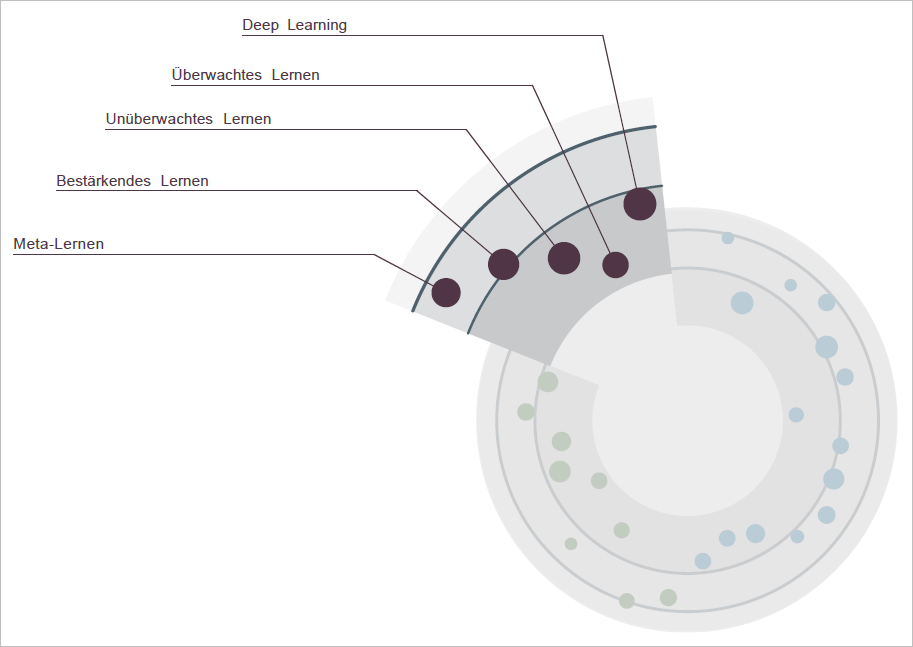
KI: Lernmethoden. Grafik: Fraunhofer Institut FOKUS.
Deep Learning
Der Begriff Deep Learning bezeichnet verschiedene Techniken zum Optimieren von künstlichen neuronalen Netzen. Durch einen komplexen Aufbau mit zahlreichen Zwischenschichten wird eine „tiefe“ Struktur geschaffen, die den Lernerfolg bedeutend verbessert. Außerdem sollen die künstlichen neuronalen Netze auch die „tiefere“ Bedeutungsebene von Eingabedaten lernen, um verlässlich auf ihnen zu arbeiten. Durch Deep Learning sind bedeutende Erfolge im maschinellen Lernen erzielt worden, die zu wichtigen Entwicklungen in der Anwendung Künstlicher Intelligenz geführt haben.
Überwachtes Lernen
Überwachtes Lernen (engl. supervised learning) beschreibt eine Art von Lernmethoden, mit denen KI-Systeme trainiert werden. Ziel ist es, dem System ein bestimmtes Verhalten anzulernen, damit es eine spezielle Aufgabe autonom lösen kann. Grundlage dafür ist eine Wissens- oder Datenbasis mit einem klar definierten Lernziel. Das KI-System wird im Lernprozess überwacht und fortwährend angepasst, um seine Leistung zu steigern. Diese Methoden entsprechen dem klassischen Ansatz der KI-System-Entwicklung und können in vielen Bereichen angewendet werden.
Unüberwachtes Lernen
Unüberwachtes Lernen (engl. unsupervised learning) stellt einen unkonventionellen Ansatz zum Training von KI-Systemen dar. Mit diesen Methoden lernt ein KI-System eine Aufgabe zu lösen, ohne dass der Lösungsweg vorher bekannt ist. Das KI-System filtert dabei Regelmäßigkeiten aus den Eingabedaten heraus und versucht auf diese Weise, Muster zu erkennen. Damit können Aufgaben bewältigt werden, an denen andere Lernmethoden scheitern. Unüberwachtes Lernen ist besonders für komplexe Anwendungsbereiche geeignet, die mathematisch schwer zu beschreiben sind.
Bestärkendes Lernen
Bestärkendes Lernen (engl. reinforcement learning) ist eine Lernmethode, die aus der Verhaltenstheorie stammt. Hierbei wird das gewünschte Verhalten des KI-Systems durch Belohnen konstruktiver Handlungen und Bestrafen destruktiver Handlungen angelernt. Hierzu wird in der Regel mit einem internen Punktestand gearbeitet. Jede richtige Handlung erhöht den Punktestand, jede falsche Handlung bedeutet Punktabzug. Ziel des KI-Systems ist es, den Punktestand zu maximieren. Mit dieser Methode trainierte Systeme werden beispielsweise in der Robotik und in Steuerungssystemen eingesetzt.
Meta-Lernen
Meta-Lernen bezeichnet Methoden, um existierende Lernalgorithmen zu optimieren. Dabei werden Lernalgorithmen auf die anfallenden Metadaten der KI-System-Entwicklung selbst angewandt. Das Ziel besteht darin, Lernalgorithmen zu verbessern und flexibler zu gestalten, sodass sie effektiver eingesetzt werden können. Der herkömmliche Entwicklungsprozess, der aufwändige händische Konfiguration erfordert, wird mit diesen Methoden beschleunigt. Meta-Lernen kommt in der Entwicklung von KI-Systemen zum Einsatz
Technologien & Algorithmen
Unter Technologien & Algorithmen werden hier die Bausteine gefasst, aus denen sich KI-Systeme zusammensetzen. In dieser Kategorie befinden sich mathematische Methoden zur Klassifizierung und Verarbeitung von Daten sowie zum Auffinden und Optimieren von Lösungen. Die einzelnen Technologien oder Optimierungsmethoden können miteinander kombiniert werden und so KI-Systeme mit innovativer Funktionalität ermöglichen.
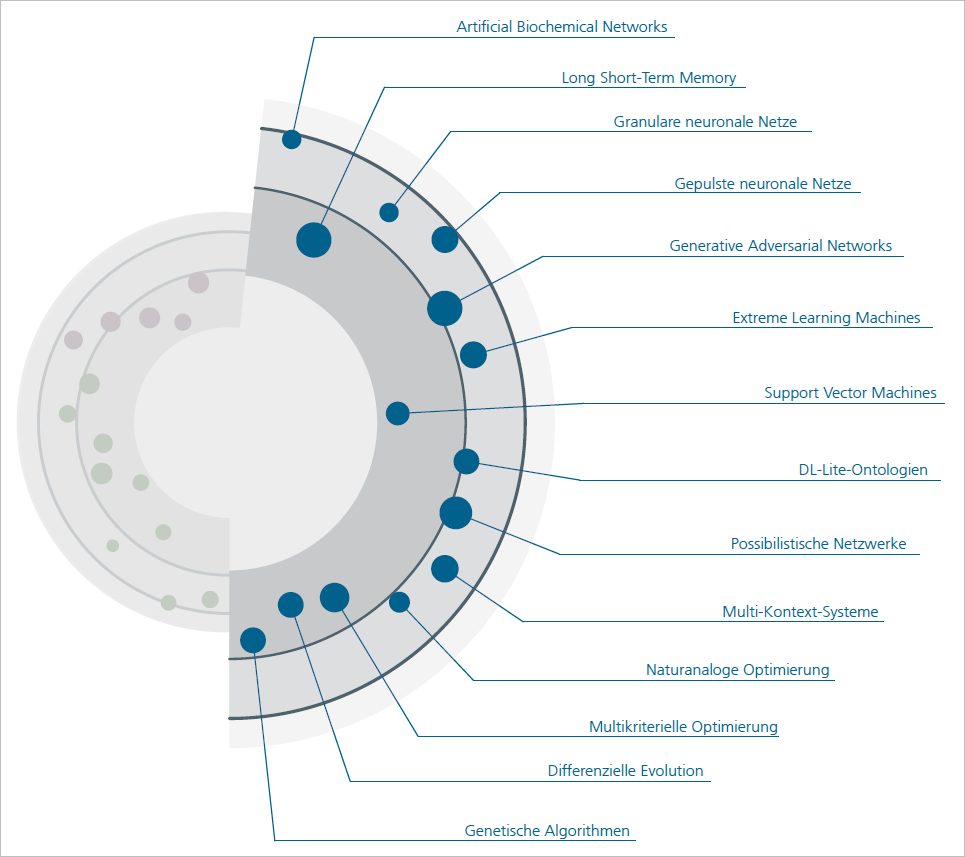
KI: Technologien und Algorithmen. Grafik: Fraunhofer Institut FOKUS.
Artificial Biochemical Networks
Artificial Biochemical Networks sind dynamische Systeme, die biochemische Prozesse in natürlichen Organismen nachahmen. Dabei wird das Verhalten von Proteinen in einzelligen Organismen simuliert. Die daraus resultierenden Systeme sind sehr flexibel und können komplexe Operationen ausführen. Ein so aufgebautes Netz kann beispielsweise gleichzeitig sensorische Eingabedaten erkennen und mechanische Operationen steuern, was Artificial Biochemical Networks für den Einsatz in der Robotik und in Steuerungssystemen interessant macht.
Long Short-Term Memory
Long Short-Term Memory ist ein dynamisches System, das auf der Architektur neuronaler Netze basiert. Es besitzt ein primitives Gedächtnis, indem in jedem künstlichen Neuron Informationen gespeichert und wieder gelöscht werden können. Signale können sich ohne Zeiteinschränkung frei im System bewegen, sodass Aussagen über zeitlich getrennte Datensätze getroffen werden können. Mit diesen Eigenschaften sind Long-Short-Term-Memory Systeme gut geeignet für die Verarbeitung von Audio und Video und für die Voraussage von Entwicklungsreihen.
Granulare Neuronale Netze
Granulare neuronale Netze können mit ungenauen und unvollständigen Datensätzen umgehen. Solche Daten fallen in großer Menge an, beispielsweise durch Sensoren im Internet der Dinge. Die Granularität der Daten bezeichnet hierbei den Detailgrad der Strukturierung, beispielsweise ob eine Adresse als Gesamtes oder in den Feldern Straße, Hausnummer und PLZ einzeln abgespeichert wird. Durch eine granulare Datendarstellung kann die reale Welt besser beschrieben und der Rechenaufwand für Operationen gesenkt werden. Granulare neuronale Netze nutzen intern unscharfe Logiken (siehe Fuzzylogik-Systeme) zur Repräsentation der Daten in der Netzstruktur. Sie finden Anwendung in Steuerungssystemen und autonomen Systemen.
Gepulste Neuronale Netze
Gepulste neuronale Netze orientieren sich noch stärker am biologischen Vorbild als andere neuronale Netze. Durch das Simulieren von Pulsen, wie sie auch in Neuronen im menschlichen Gehirn vorkommen, werden Impulse durch künstliche Neuronen weitergeleitet. Dabei wird eine zeitliche Dimension in das neuronale Netz eingebettet, sodass es mit sequenziellen Daten umgehen kann. Mit gepulsten neuronalen Netzen können biologische Nervensysteme simuliert und auf informatische Anwendungen übertragen werden, beispielsweise in der Robotik oder bei künstlichen Immunsystemen.
Generative Adversarial Networks
Generative Adversarial Networks haben das Ziel, automatisiert realistisch erscheinende Daten, beispielsweise Bilder, zu generieren. Sie bestehen aus zwei neuronalen Netzen, einem generativen und einem diskriminierenden Netz. Das generative Netz erzeugt Daten, die von dem diskriminierenden Netz auf ihre Qualität hin bewertet werden. Die Netze stehen in Konkurrenz zueinander und erzeugen in ihrer Kombination sehr realistisch erscheinende Ergebnisse. Die Technologie wird beispielsweise in der Generierung von fotorealistischen Bildern und Videos angewendet.
Extreme Learning Machines
Extreme Learning Machines bezeichnet eine Klasse von Technologien zur Datenklassifikation. Sie bauen auf einer einfachen Systemarchitektur auf und wenden ein besonderes Lernverfahren an, bei dem die Klassifikation der Eingabedaten in der Regel in einem einzigen Schritt durchgeführt wird. Extreme Learning Machines zeichnen sich durch einen schnellen Lernprozess aus. Sie werden beispielsweise zur Spracherkennung und zur Prognose von Entwicklungen (beispielsweise für Börsenkurse oder physikalische Simulationen) eingesetzt.
Support Vector Machines
Support Vector Machines sind mathematische Verfahren zur Klassifikation von Daten. Die Eingabedaten entsprechen dabei mathematischen Vektoren in einem Vektorraum. Dieser wird durch numerische Analyse in Bereiche aufgeteilt, die die verschiedenen Klassen der Daten repräsentieren. Dabei lassen sich nicht nur numerische Daten klassifizieren, sondern insbesondere auch Text und Bilder. Die Methode wird ständig weiterentwickelt und findet breite Anwendung in der Mustererkennung.
DL-Lite-Ontologien
Um Objekte und ihre Beziehungen zueinander maschinenauswertbar zu beschreiben, werden formale Sprachen benötigt. Bei DL-Lite-Ontologien (DL: description language) werden solche formalen Sprachen in Wissensdarstellungen (Ontologien) eingebettet, die für niedrige Rechenkomplexität optimiert sind. Das erleichtert Abfrage-Operationen und ebnet den Weg der Künstlichen Intelligenz zu Geräten mit geringer Rechenkapazität, wie beispielsweise im Bereich Internet der Dinge.
Possibilistische Netzwerke
Mit possibilistischen Netzwerken lässt sich Wissen über unvollständige oder ungenaue Daten abbilden und verarbeiten. Dabei werden basierend auf Daten Aussagen abgeleitet und eine Wahrscheinlichkeit errechnet, mit der die Aussagen zutreffen. Mit diesem Ansatz werden Abfragen auf Daten ermöglicht, die sonst wegen ihrer mangelnden Datenqualität unbrauchbar wären. Die possibilistischen Netzwerke können per Hand von Experten oder automatisiert von Maschinen erstellt werden, und finden ihre Anwendung in wissensbasierten Systemen.
Die Gefahr, dass der Computer so wird wie der Mensch, ist nicht so groß wie die, dass der Mensch so wird wie der Computer. (Konrad Zuse)
Multi-Kontext-Systeme
Multi-Kontext-Systeme ermöglichen es, Systeme mit unterschiedlich strukturierten Daten zu kombinieren. Dabei werden Daten beim Übertragen in eine neue Wissensbasis automatisch angepasst, sodass das Zielsystem sie nutzen kann. Zusätzlich können logische Operationen auf diesen Daten angewendet werden, womit Multi-Kontext-Systeme eine komplexe Interaktion zwischen den einzelnen Systemen ermöglichen. Sie kommen in wissensbasierten Systemen und Multiagenten-Systemen zum Einsatz.
Naturanaloge Optimierung
Naturanaloge Optimierungsalgorithmen nutzen Mechanismen aus der Tierwelt, um Optimierungsaufgaben effizient zu lösen. Sie modellieren das Verhalten von Tieren wie Ameisen oder Fischen, die in einem Schwarm emergente Intelligenz aufweisen. In diesen KI-Verfahren werden die einzelnen Individuen in den Schwärmen durch sogenannte intelligente Agenten dargestellt, die auf eine gemeinsame Problemlösung hinarbeiten. Diese Algorithmen lassen sich auf komplexe Probleme der realen Welt übertragen, beispielsweise in der Logistik und im Management sowie in der Optimierung von Routen und Prozessen.
Multikriterielle Optimierung
Multikriterielle Optimierung findet ihre Anwendung in komplexen IT-Systemen, die mehr als nur eine einzige Zielsetzung haben. Mit diesen Verfahren wird versucht, zwischen unterschiedlichen Teilzielen eines Systems ein optimales Gleichgewicht zu finden. Diese Teilziele können miteinander in Konflikt stehen, wie beispielsweise der Benzinverbrauch und die Geschwindigkeit eines Autos. Vor allem IT-Systeme, die die reale Welt abbilden oder zur Steuerung eingesetzt werden, setzen multikriterielle Optimierung zur Entscheidungsfindung ein. Beispiele dafür sind autonome Systeme sowie Systeme zur Entscheidungsunterstützung.
Differenzielle Evolution
Differenzielle Evolution ist eine Methode zur Lösung von Optimierungsaufgaben, die auf mathematischen Prinzipien basiert. Aus einer anfangs zufälligen Menge von Lösungskandidaten für ein zu optimierendes Problem werden in einem iterativen Prozess neue Lösungsvarianten mit einer einfachen mathematischen Formel erschaffen. Das Verfahren benötigt nur wenige einzustellende Steuerparameter, ist leicht implementierbar und liefert gute Ergebnisse, weswegen es beispielsweise im Ingenieurwesen, zum Hardwareentwurf und in der Robotik eingesetzt wird.
Genetische Algorithmen
Genetische Algorithmen sind Verfahren, die zur Lösung von komplexen Optimierungsaufgaben eingesetzt werden, wie beispielsweise zur Platzierung von Containern auf einem Containerschiff. Jeder Lösungskandidat für das zu optimierende Problem wird hierbei durch einen genetischen Code repräsentiert. Die erfolgreichsten Kandidaten werden ausgewählt und ihre Codes nach biologischen Mutationsprinzipien kombiniert, bis ein Lösungskandidat die Anforderungen des Problems erfüllt. Genetische Algorithmen kommen beispielsweise bei Anwendungen in der Logistik und Wirtschaft zum Einsatz.
Systeme & Architekturen
Kombiniert man die oben beschriebenen KI-Technologien, so entstehen komplexe Systeme und Architekturen. Diese erlauben es, mit mehreren Technologien eine übergeordnete Funktion zu realisieren. Bewährte Systeme und Architekturen können über längere Zeiträume hinweg relevant bleiben, auch wenn einzelne Komponenten ausgetauscht werden.
KI: Systeme und Architekturen. Grafik: Fraunhofer Institut FOKUS.
Intelligente Agenten
Intelligente Agenten sind autonome Computerprogramme. Sie nehmen ihre Umgebung beispielsweise durch Sensoren wahr und können nach vorbestimmten Regeln handeln. Die Umgebung eines intelligenten Agenten kann die reale Welt oder auch ein virtueller Kontext sein. Ein intelligenter Agent kann auf seine Umgebung einwirken und Wissen ansammeln, welches für zukünftige Entscheidungen verwendet werden kann. Ein beispielhaftes Anwendungsfeld für intelligente Agenten ist das Internet der Dinge.
Multiagentensysteme
Bei Multiagentensystemen handelt es sich um interagierende intelligente Agenten (siehe Intelligente Agenten), die ein Netzwerk formen. Die Agenten tauschen untereinander Informationen aus und verfolgen ein kollektives Ziel, wobei jeder einzelne Agent zusätzlich unterschiedliche Unterziele besitzen kann. Im Zusammenwirken entsteht ein emergentes Verhalten. Multiagentensysteme sind robust und flexibel und werden beispielsweise in der Logistik und der Simulation eingesetzt.
Expertensysteme
Expertensysteme sind eine Form von Systemen, die Informationen eines Experten besitzen. Dabei bezieht sich das Wissen des Systems meist auf ein einzelnes Fachgebiet. Ein Expertensystem kann Wissen aufbauen, Probleme lösen und dem Nutzer die gefundenen Lösungen erklären. Expertensysteme werden seit Langem in der Praxis eingesetzt. Das Anwendungsgebiet ist breit gefächert über alle Bereiche der Arbeitswelt hinweg.
Entscheidungsunterstützungssysteme
Entscheidungsunterstützungssysteme (engl. decision support systems) sind KI-Systeme, die bei der Entscheidungsfindung helfen. Dabei werden Sachverhalte der realen Welt modelliert und datengestützte Handlungsempfehlungen abgegeben. Relevante Informationen werden aufbereitet, ausgewertet und eine zielführende Strategie wird entworfen. Beispielhafte Anwendungen finden sich etwa in der Finanzwelt oder bei persönlichen Assistenten.
(Business) Rule Management Systems
(Business) Rule Management Systems (BRMS) bilden Teile der realen Welt in einem Modell ab, in dem Organisationen ihre geschäftsbezogenen Prozesse hinterlegen können. Durch Einbezug von definierten Regeln und geltenden Randbedingungen können Geschäftsprozesse transparenter und deren Verwaltung einfacher gemacht werden. Anhand der Simulation von Abläufen können eventuelle Schwächen oder Fehlplanungen leichter identifiziert werden. BRMS werden daher hauptsächlich in der Wirtschaft eingesetzt.
Künstliche Immunsysteme
Künstliche Immunsysteme sind adaptive KI-Systeme, die IT-Systeme und Infrastrukturen schützen sollen. Sie ähneln in Struktur und Funktionsweise ihren biologischen Gegenstücken. Sie können aus vergangenen Ereignissen lernen, Wissen speichern und daraus neue Regeln zum Handeln ableiten. So verbessern sich Künstliche Immunsysteme durch jedes Problem, das ihnen gestellt wird. Sie können beispielsweise zum Entwickeln autonomer Sicherheitssysteme eingesetzt werden.
Fuzzylogik-Systeme
Fuzzylogik-Systeme sind KI-Systeme, die zusätzlich zur binären Logik auch Fuzzylogik nutzen. Fuzzylogik bezeichnet eine Logik, die nicht nur binäre Zustände (0 oder 1) kennt, sondern auch Zwischenformen. Durch Fuzzy-Variablen ist es beispielsweise möglich, den logischen Bereich zwischen warm und kalt besser zu beschreiben, was mit binärer Logik nicht möglich ist. Sachverhalte in der realen Welt lassen sich mit in Fuzzylogik modellierter Unschärfe genauer darstellen und simulieren. Fuzzylogik findet breite Anwendung in Steuerungssystemen und in der Verarbeitung natürlicher Sprache.
Quantenlogik-Systeme
Quantenlogik-Systeme betten Quantenlogik und Quantenalgorithmen in KI-Systeme ein, um diese im Wesentlichen leistungsfähiger zu machen. Auch die KI-Bereiche der Suche und Optimierung können von der Anwendung von Quantenalgorithmen profitieren. Gewisse Prozesse der realen Welt können sogar erst durch Quantenlogik abgebildet werden. Quantenlogik-Systeme können perspektivisch beispielsweise bei der Verarbeitung natürlicher Sprache und in Prozesssimulationen eingesetzt werden.
Meta-Programmierung
Meta-Programmierung bezeichnet KI-Systeme, die Software entwickeln. Ausgehend von klar definierten Schnittstellen und Zielen schreibt und testet ein KI-System ein Programm, das einem definierten Anforderungskatalog entspricht. Dazu gehören die Modellierung der Softwarearchitektur, die Generierung von Programmcode, die Optimierung der Laufzeit und das Speichermanagement. Meta-Programmierung spart signifikant Entwicklungszeit, ist aber mit erheblichem Konfigurationsaufwand verbunden.
(Lizenz CC BY 3.0)
Zur vollständigen Studie.










Kommentar hinterlassen zu "Künstliche Intelligenz: Was ist möglich? Was hat Potenzial? Und was ist zu tun?"