Mit dem Grundsatzpapier vom September 2022 zum Einsatz von XML in der Verlagsbranche räumt die Peer Group Produktion der IG Digital auf mit dem Paradigmenstreit „XML first oder XML last“. Die wichtigste Botschaft lautet: Es gibt eigentlich kein Argument mehr gegen XML als strategische Datenbasis für Verlage.
Aber es gibt viele Wege, die zum Ziel führen. Und: für jeden Verlag gibt es den richtigen (XML-)Prozess.
Im zweiten Teil der Serie zum XML-Einsatz im Verlag beleuchtet Tobias Ott, Geschäftsführer der pagina GmbH Publikationstechnologien und Co-Autor des Grundsatzpapiers, die zentralen Aspekte, die bedacht sein wollen, um den passenden XML-Workflow im Verlag einzuführen.

Tobias Ott ist seit 1996 Geschäftsführer und Gesellschafter der Pagina GmbH Publikationstechnologien (Tübingen). Er studierte an der Hochschule der Medien (damals: Fachhochschule für Druck) in Stuttgart Verlagswirtschaft, Verlagsherstellung sowie Werbetechnik und Werbewirtschaft. Ott ist auch Co-Autor eines neuen Grundsatzpapiers zum Einsatz von XML in der Verlagsbranche. Entstanden ist es in der Peer Group Produktion der IG Digital im Börsenverein. (Foto: Pagina GmbH)
Unsere Branche vibriert. Die Herausforderungen sind groß. In der Zange von wirtschaftlichen Zwängen und dramatisch steigenden Rohstoffpreisen auf der einen Seite und der Notwendigkeit, Teil der digitalen Gesellschaft zu werden und barrierefrei zu publizieren, auf der anderen Seite, fahren viele Verlage derzeit „auf Sicht“. Dabei wäre in vielen Fällen die Einführung eines effizienten XML-Workflows ein wirtschaftlich wie strategisch gleichermaßen sinnvoller Weg aus dem Dilemma.
XML ist nicht nur zur Kostensenkung da
Um es gleich vorweg zu nehmen: XML ist kein Allheilmittel. Und bei weitem nicht in jedem Verlag führt die Einführung von XML automatisch zu Kostensenkungen. Oder andersherum gesagt: Die Verlage, bei denen das Einsparpotenzial durch XML hoch ist, haben ihre Produktionsweise oft schon vor vielen Jahren umgestellt. Doch die Technologie hat sich in den vergangenen Jahren massiv weiterentwickelt, sodass effiziente XML-Workflows heute für einen Großteil unserer Branche zur Verfügung stehen und die Vorstufenkosten signifikant senken können.
Gleichzeitig aber steigen die Anforderungen an den Verlags-Content von Jahr zu Jahr. Immer häufiger reicht es für digitale Publikationen nicht mehr aus, die Inhalte aus den imprimierten Satzdaten auszuleiten. Nicht nur aufgrund der Notwendigkeit der Barrierefreiheit: Die Digitalstrategie eines Verlagshauses sollte zunehmend die Richtung nehmen, dass digitale Angebote keine 1:1-Abbildungen der Printinhalte sind, sondern eigenständige Publikationen.
Am deutlichsten wird das derzeit im Bereich der Bildungsmedien: Immer lauter wird der Ruf nach adaptiven Lernkonzepten, nach individuellen Lernpfaden für jede Schülerin und jeden Schüler. Um in diesem hochrelevanten Zukunftsmarkt mitspielen zu können, bedarf es ein Vielfaches an (digital verfügbaren) Aufgaben und Lösungen im Vergleich zu der Anzahl an Aufgaben, die im Schulbuch abgebildet werden können. Hier sind also neue redaktionelle Konzepte gefordert, ein XML-last-Ansatz führt nicht weiter.
Wir sehen: Neben dem herstellerisch-kaufmännischen Aspekt des Einsatzes von XML gibt es auch einen zweiten, strategischen Aspekt. Hierbei handelt es sich häufig um nichts weniger, als die Zukunft des Verlages langfristig sicherzustellen in einer Welt, die nach digitalen Lösungen fragt.
In die Entscheidung bezüglich der richtigen Digitalstrategie für die Zukunft fließen zahlreiche Aspekte mit ein, die eine Einzelfall-Betrachtung unbedingt sinnvoll erscheinen lassen: Verlagsgröße, Anforderungen der Zielgruppe (der Leserschaft ebenso wie des Marktsegments, zum Beispiel die Open-Access-Anforderungen im Bereich der Wissenschaft), strategische wie kaufmännische Ziele, Qualifikation der Mitarbeitenden und vieles mehr wollen berücksichtigt werden.
Und gleichzeitig ist es genau diese Grundannahme, dass der eigene Verlag „ganz besonders“ arbeite, nicht vergleichbar sei – positiv gesprochen also das Herzblut, mit dem wir an lieb gewordenen Verlags-Eigenheiten und -Abläufen hängen, kritischer formuliert: die Akzeptanz von scheinbaren Sachzwängen –, die unsere Branche lähmt und von einem systematischen Weg durch die digitale Transformation abhält.
Weitere Lösungen, Impulse und Erfahrungsberichte lesen Sie im Channel Strategie & Transformation von buchreport und Channel-Partner Publisher Consultants.
Hier mehr…
Welcher XML-Prozess für wen?
Muss also wirklich jeder Verlag immer wieder bei Null anfangen? Und eine „digitale Agenda“ aufsetzen, die nicht oder nur kaum von den Erfahrungen anderer Verlage profitieren kann? Wir haben uns in der Pagina GmbH in den vergangenen Jahren intensiv mit dieser Frage auseinandergesetzt – in zahlreichen Digitalisierungsprojekten, aber auch im Rahmen der Lehrtätigkeit an der Hochschule der Medien. Es war die Suche nach Mustern, nach den richtigen Kriterien und Kategorien, die eine rasche Verortung eines Verlages ermöglichen sollen. Aus dieser Verortung sollte sich dann eine erste Empfehlung für eine Vorgehensweise ableiten lassen, mit dem Ziel, ein Transformationsprojekt nicht „bei Null“ beginnen zu lassen, sondern dabei auf die mannigfachen Erfahrungen der Branche zurückgreifen zu können.
Das nachfolgende Modell ist das Ergebnis dieser Überlegungen. Es setzt an dem Punkt an, an dem die grundsätzliche Entscheidung für XML als technologische Grundlage einer künftigen Content-Strategie und ggf. auch der Medienproduktion gefallen ist.
Doch damit fängt die Arbeit erst richtig an: Welche Arbeitsweise – XML first oder XML last – passt zu meinem Verlag und zu meinem Verlagsprogramm? Welche XML-Struktur ist die richtige? Gibt es einen Branchenstandard, auf den ich zurückgreifen kann, oder muss ich eigene Strukturen aufbauen? Wie groß wird der Einspareffekt sein, den ich durch XML erzielen kann – oder wird meine Printproduktion verteuert? Welche IT-Infrastruktur (MAM/CMS/…) ist die richtige?
Mit den folgenden grundsätzlichen Fragestellungen können wir uns diesen Themen sehr schnell nähern. Die Fragestellungen dienen der Einordnung des eigenen Verlags und Programms in eine Matrix. Hier geht es also vor allem darum, die richtigen Kategorien für die Achsen der Matrix zu finden.
Die y-Achse: Automation der Medienproduktion
Die erste Kategorie – nachfolgend auf der y-Achse aufgetragen – ist naheliegend, denn sie betrifft den möglichen Automationsgrad der Medienproduktion (für Print und digital) und damit das voraussichtliche Einsparpotenzial: Die Metrik reicht dabei von „die Produkte unseres Verlages sind stark layout-getrieben“ bis zu „die Inhalte unseres Verlages können regelbasiert/automatisiert gerendert werden“. Dabei geht es nicht darum, einen präzisen Wert zu ermitteln, sondern um eine grundsätzliche Verortung: Ein Belletristik-Verlag wird, ebenso wie ein juristischer Fachverlag, seine Medienproduktion eher automatisieren können als ein Kochbuch- oder Schulbuchverlag, bei denen das (individuelle Seiten-)Layout eine ganz andere Funktion bei der Inhaltsvermittlung oder bei der Kaufentscheidung übernimmt.
Damit haben wir bereits eine erste wichtige Kategorie identifiziert: Denn je höher der erhoffte Automationsgrad in der Medienproduktion, umso eher lohnt es sich, XML zur Grundlage aller Medienausleitungen (also auch Print) zu machen: Das wäre die klassische XML-first-Produktion.
Doch ganz so einfach ist es leider nicht. Wenden wir uns also der x-Achse zu.
Die x-Achse: Aufbau des Mediums
Diese Kategorie ist erläuterungsbedürftig. Es geht um die Frage, wie unsere Verlagsprodukte aufgebaut sind – als ein sequenzieller Text oder als Summe kleiner, unabhängiger Einheiten.
Es ist der Charakter eines Buches, das als physisches Produkt aus einer Aneinanderreihung von Seiten bzw. Blättern besteht, Inhalte in einer definierten Reihenfolge darzubieten. Diese Abfolge der Inhalte findet sich idealerweise bereits im Manuskript. Häufig ist diese Reihenfolge, zum Beispiel von Kapiteln, verbindlich und gibt den Lesepfad vor. Weder in einem Lehrwerk, in dem die einzelnen Kapitel hinsichtlich des Lernfortschritts aufeinander aufbauen, noch in einem Roman mag man sich eine andere Sequenz als die von der Autorin oder dem Autor vorgegebene vorstellen.
Doch das ist nicht immer so. Wenn wir uns von der Klammer des Buches lösen, für das die Inhalte stets in eine Anordnung gebracht werden müssen, so stellen wir fest, dass das gedruckte Werk häufig nur eine mögliche Anordnung der Inhalte von vielen verschiedenen Möglichkeiten ist. Die Rezepte in einem Kochbuch, die Bastelanleitungen in einem Ratgeber, die Aufgaben in einem Schulbuch und auch die Artikel einer Zeitschrift haben alle einen eigenständigen Charakter, „funktionieren“ also auch ohne den Kontext. Dann ist nicht mehr das gesamte Werk die kleinste vermarktbare Einheit; die Informationseinheit (oft auch als MIU, minimum information unit, bezeichnet) ist deutlich kleiner.
Diese Erkenntnis ist nicht neu – aber sie hat weitreichende Konsequenzen. Während sich diese Erkenntnis auf die Printproduktion nicht auswirkt – die einzelnen Informationseinheiten werden ja weiterhin, wie in der Vergangenheit auch, in einem sequenziellen Manuskript an den Verlag geliefert und in dieser Reihenfolge gesetzt und gedruckt –, hat sie massive Auswirkungen auf die Konzeption und Erstellung von elektronischen Medien:
- Bei einem Werk, das sequenziell aufgebaut ist, in dem die Reihenfolge der Inhalte also den einzig möglichen logischen Rahmen vorgibt, wird auch das digitale Produkt identisch aufgebaut sein. Die E-Book-Ausgabe eines Romans soll bitte denselben Inhalt in derselben Anordnung enthalten wie die Print-Ausgabe.
- Ganz anders bei einem Produkt, das aus kleinen, unabhängigen Einheiten („Topics“) aufgebaut ist: Hier ist die Anordnung im Buch nur ein möglicher Rahmen von vielen, sie spielt für das digitale Produkt keine Rolle, ist vielleicht sogar eher störend. Wir müssen das einzelne Topic also zu einer digital adressierbaren Einheit machen, die unabhängig vom Kontext gefunden und präsentiert werden kann.
Verlagsprogramme richtig verorten
Erstellen wir aus diesen beiden Achsen eine Matrix in Form eines Koordinatensystems und versuchen wir uns an einer groben Verortung der Verlagssparten, so ergibt sich eine interessante Landkarte unserer Branche:
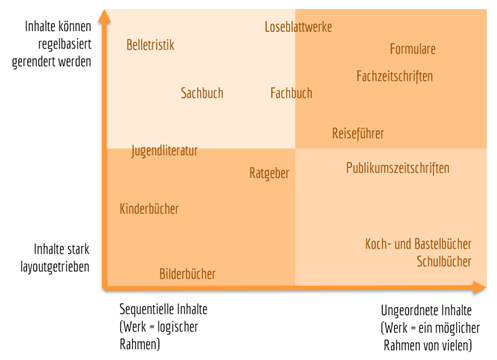
Wir ahnen, dass die automatisierte Verarbeitung von Verlagsinhalten im linken oberen Quadranten deutlich einfacher zu lösen sein wird als im rechten unteren Feld. Und tatsächlich betrifft die Frage nach der Komplexität nicht nur die maschinellen Prozesse, sondern meist auch die redaktionellen und Lektorats-Prozesse – bis hin zu konzeptionellen Fragen des Aufbaus und Leistungsumfangs digitaler Produkte und Dienstleistungen.
Wir haben also ein hilfreiches Modell gefunden, in dem wir unseren eigenen Verlag verorten können und aus dem sich hoffentlich Handlungsempfehlungen ableiten lassen. Dabei gilt:
- Je weiter links und je weiter oben in der Matrix sich das eigene Verlagsprogramm wiederfindet, umso schneller lässt sich eine XML-first-Arbeitsweise einführen und umso eher sind damit auch Einspareffekte verbunden.
- Je weiter rechts unten in der Matrix wir uns befinden, desto schwieriger wird der Einsatz von XML im Satz, desto weniger Nutzen zieht der Verlag also für die Buch-Produktion aus XML – nicht selten kann sich dann eine Satz-Produktion durch XML first sogar verteuern.
Die meisten der Verlage im rechten unteren Quadranten entscheiden sich daher in der Einführungsphase für einen XML-last-Prozess; sowohl aus herstellerischen Gründen bzw. dem Fehlen von Einsparpotenzialen im Satz, als auch deshalb, weil ein XML-first-Prozess völlig andere redaktionelle Abläufe implizieren würde – gehen wir doch in dieser Phase immer noch von einem gelieferten Manuskript aus und nicht von separat vorliegenden, kleinen Informationseinheiten.
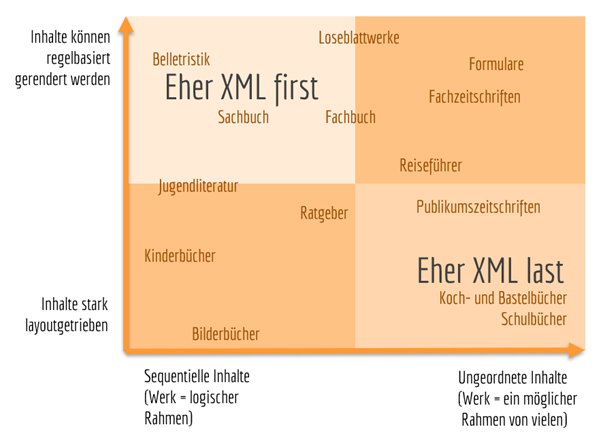
Gleichzeitig bringt uns diese Erkenntnis in ein Dilemma: Wenn XML last doch eine Konvertierung der Satzdaten aus dem finalen Umbruch bedeutet – und damit eben keine unabhängigen MIUs generiert, sondern zunächst eine XML-Datei in genau der Sequenz des Buches – erhalte ich dann durch XML last überhaupt die Daten, die ich mir erhoffe? Oder sind nicht aufwendige Nacharbeiten an den Daten erforderlich; verlagere ich die notwendigen redaktionellen Arbeiten nicht schlicht auf die Phase nach dem Satz, anstatt sie gleich in der Manuskriptphase zu erledigen?
Strategiefragen jenseits von »first« und »last«
Dieses Dilemma lässt viele Verlage ratlos zurück. Doch es lässt sich gut auflösen, wenn wir uns klarmachen, dass die vorliegende Matrix vor allem die herstellerischen Aspekte der Content-Verarbeitung im Verlag zum Inhalt hat.
Solange also in einem Verlag die Erstellung von medienneutralen Daten in der Verantwortung der Herstellung liegt – und der Nutzen des Einsatzes von XML vor allem in der Optimierung herstellerischer Abläufe gesehen wird –, so lange gibt diese Matrix eine sehr gute Orientierung. Und tatsächlich erfolgt in fast allen Verlagen die Einführung von XML zunächst über die Herstellung.
Doch ist XML wirklich „nur“ ein technisches Thema? Ist mit dem medienneutralen Vorhalten von Inhalten wirklich schon die hinreichende Grundlage für eine erfolgreiche Digitalstrategie geschaffen?
Wir kommen nicht umhin, uns mit einem weiteren Aspekt – und damit mit einer dritten Achse der Matrix – zu beschäftigen: dem Anspruch des Verlages an den Aufbereitungsgrad seiner Daten.
Wir erinnern uns: Die eigentliche Stärke von XML ist es, dass wir die Inhalte semantisch beschreiben können, mit „Welt-Wissen“ anreichern können. Damit können wir es Maschinen ermöglichen, Fragen an die Daten (auch ohne künstliche Intelligenz) zu beantworten, die „Welt-Wissen“ erfordern.
Es macht einen fundamentalen Unterschied, ob wir den Text „Karottensuppe Zutaten 500gr Karotten Gemüsebrühe Sahne Salz Pfeffer“ in XML nur formal abbilden, also beispielsweise so:

oder ob wir semantische Einheiten bilden, wie zum Beispiel:

Dies lässt sich – je nach Anforderung an die Inhalte und die gewünschten digitalen Ausleitungen und Abfragen – beliebig erweitern:

Schon an diesem einfachen Beispiel wird deutlich, dass es sich bei der semantischen Strukturierung um redaktionelle, nicht um herstellerische Arbeit handelt. Ab einem bestimmten Anspruch des Verlages an seinen digitalen Content kommen wir also um eine Einbeziehung des Lektorats nicht umhin. Und wir werden erneut auf unser oben beschriebenes Dilemma gestoßen: Eine formale XML-Ausleitung aus den Satzdaten (XML last) wird sich technisch lösen lassen, die Aufteilung der Inhalte in MIUs, ihre Anreicherung mit Metadaten und vor allem die semantische Strukturierung der Inhalte wird sich aus Satzdaten dagegen nicht ohne weiteres ausleiten lassen.
Was die Redaktion mit XML zu tun hat
Fügen wir also die dritte Achse ein (s. folgende Grafik). Während die ersten beiden Achsen die „IST-Analyse“ unserer Daten darstellen – welcher formalen Art sind unsere Inhalte – beschreibt die z-Achse den „SOLL-Zustand“: Haben wir als Verlag den Anspruch, die nicht-sequenziellen Inhalte tatsächlich in einzelnen XML-Informationseinheiten abzuspeichern? Verfolgen wir das Ziel, die Daten semantisch zu strukturieren und damit über die Bedürfnisse des Satzes hinaus zu veredeln und für eigenständige digitale Produkte vorzubereiten?
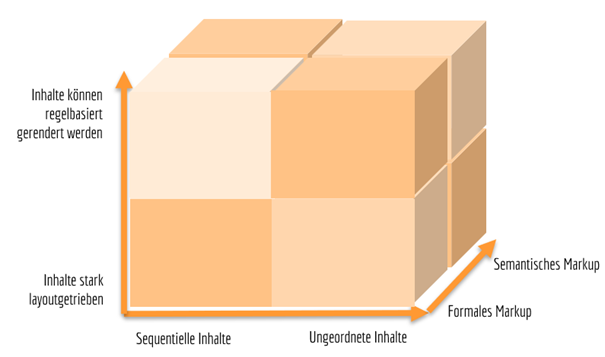
Wir könnten die z-Achse als die „Lektorats-Achse“ bezeichnen, denn je weiter wir uns auf der z-Achse nach hinten bewegen, umso wichtiger wird eine Einbeziehung des Lektorats in die Aufbereitung der Inhalte. Damit scheint der alte Konflikt zwischen Herstellung und Lektorat neu befeuert zu werden. Das aber sollten wir unbedingt vermeiden. Vielmehr sehen wir, dass eine „Digitale Agenda Verlag“ nur durch das Zusammenwirken aller Abteilungen möglich ist und sich nicht auf ein technisches Problem reduzieren lässt.
Gleichzeitig gilt weiterhin: Bei weitem nicht alle Verlagssparten stehen vor der Notwendigkeit der semantischen Gliederung ihrer Daten, um erfolgreiche digitale Produkte zu erstellen. Ein Belletristik-Verlag wird mit einem formalen Markup (und gut gepflegten Metadaten) sehr weit kommen. Für einen Schulbuch- oder einen juristischen Fachverlag reicht das dagegen mit Sicherheit nicht aus.
Hilfreicher ist es daher, die dritte Achse als die „Strategie-Achse“ zu verstehen, als eine Ausbaustufe, die wahrscheinlich nicht gleich am Anfang eines Change-Prozesses umgesetzt werden muss, wohl aber als klares Ziel definiert sein sollte (s. folgende Grafik).
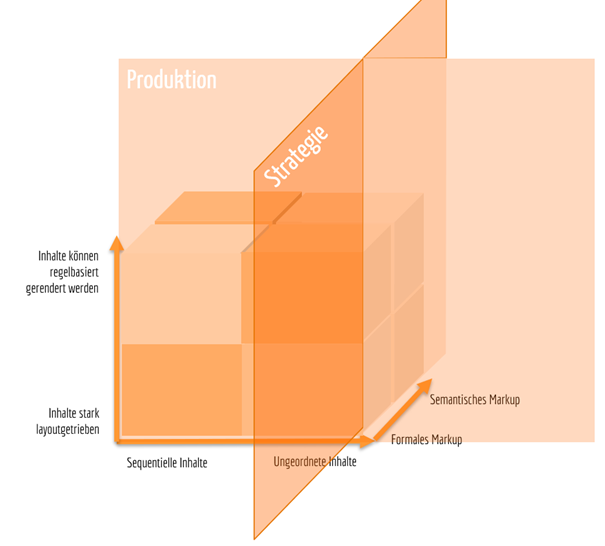
So ergibt sich aus der Verortung der Verlagsinhalte in technischer und struktureller Hinsicht in Kombination mit der Verlagsstrategie ein Zielbild, das die Frage nach der Produktionsmethode (XML first oder XML last) zunehmend in den Hintergrund treten lässt. Stattdessen wirft es die Frage nach dem gesamten Content-Entstehungsprozess auf sowie nach einem zukunftsweisenden Verlagsverständnis, das ganz selbstverständlich alle Abteilungen einbezieht. Und es legt eine zentrale IT-Infrastruktur in Form eines Redaktions-/CMS-/MAM-Systems nahe oder macht sie vielleicht sogar erforderlich.
Die Aspekte rund um „XML und Content Management Systeme“ sind Gegenstand des dritten Teils der Artikelserie.










Kommentar hinterlassen zu "XML-Workflows im Verlag: Die Vermessung der Verlagswelt"